研究方向:涉及信号和信息的“感知获取、”“处理”、“传输”、“评价”与“认知”等过程。具体如下:
(内容一)感知:计算智能成像、光谱成像、仿生成像、3D成像;
(内容二)处理:视觉处理、图像重构、脑电处理、,脑机接口;
(内容三)传输:语义通信;
(内容四)评价:图像语义评价;
(内容五)认知:类脑语义网络、场景理解。
(主要研究内容之一 ━┅ 感知):
方向一:计算智能成像、光谱成像
将孔径编码、曝光编码、光谱混叠等技术有机结合,能够高效获取光谱信息,保证光谱数据的重建精度。该方向主要研究如何实现空-时-谱信息的高分辨协同获取,探索多维信号先验信息的挖掘和表达方法,以及利用先验信息反演解码的策略。
方向二:仿生成像
仿生动态成像技术具有快速、大动态范围成像特性,可有效克服传统相机常遇到的运动模糊、过曝等问题。模拟视网膜感光特性,设计仿生动态感光芯片,以类神经元脉冲响应捕获运动信息;面向脉冲信号,研究基于第三代神经网络(即脉冲神经网络)的智能检测、识别技术。该新技术相比于传统成像在机器视觉任务中表现更优秀,尤其是在高速运动目标捕获、高/低光照环境信息采集方面具有巨大优势。
仿生动态成像-智能识别一体化系统组成
方向三:基于深度学习的结构光和DVS相机的深度获取及三维重建:
高精度深度信息快速获取能够推动我国在3D深度信息获取领域的技术发展和产业链扩展,具有重大意义。结构光方法面向高精度的3D场景信息获取。研究复合结构光编码模板的主动式深度获取方法,设计稠密鲁棒的光栅模板,开展亚像素级的匹配方法研究,构建并行处理结构,通过多粒度的模板匹配实现高精度的深度数据并行计算。特别是结合深度学习方法,开展面向无监督场景的深度获取。同时利用最新的DVS高速运动目标成像机制,开展基于事件的动态视觉传感器(DVS)的深度获取方法,利用深度学习算法实现对高速运动目标的的深度/距离信息快速获取。
双目DVS立体匹配系统
(研究内容之二 ━┅ 处理):
方向一:基于模型驱动深度神经网络的图像和视频处理与增强方法
由于环境光照条件受限、相机和景物相对运动等因素影响,相机拍摄得到的图像通常含有噪声和模糊,导致难以正确分辨图像中的目标。从低质量图像恢复出原始高清晰的图像,在视频监控、计算机视觉、健康医疗等领域具有重要应用,是实现高分辨率遥感对地观测、精准图像/视频模式识别的重要前提。针对降质图像/视频处理与增强,近年来基于深度神经网络的图像和视频处理方法取得了较好的图像恢复效果,但是也存在深度神经网络“黑箱”问题,即模型难以解释,无法利用领域知识的问题。为此,研究充分利用图像视频处理和增强的领域知识的方法,并结合数据驱动深度学习框架,研究基于模型驱动深度神经网络的图像/视频降噪、去模糊和超分辨方法。
基于模型驱动深度神经网络图像恢复方法
基于深度神经网络的图像去噪算子
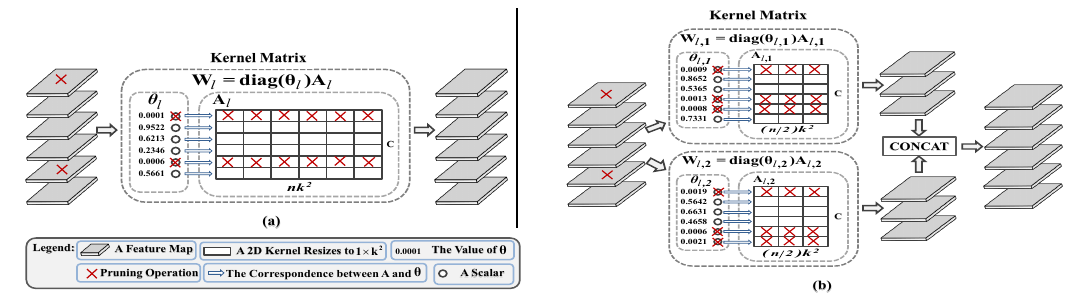
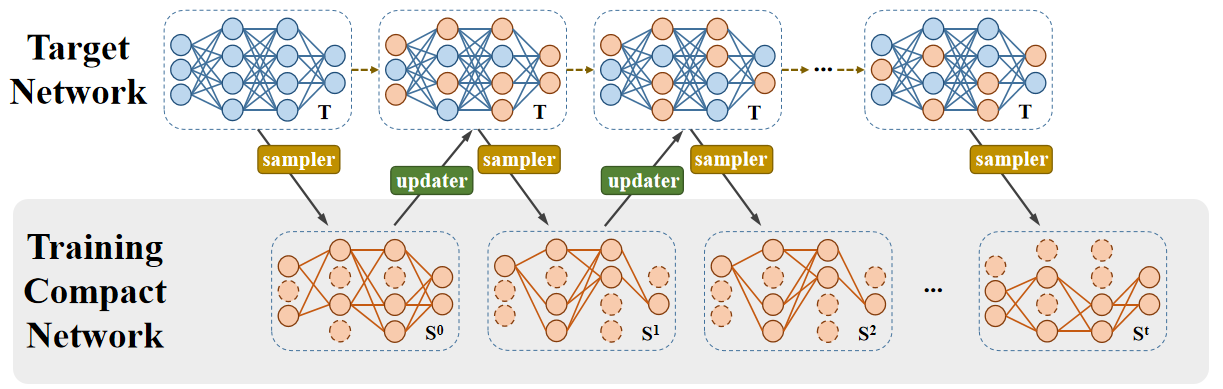
方向二:深度神经网络模型剪枝与模型结构搜索
针对该问题,我们提出了基于模型参数稀疏性的深度网络剪枝方法,利用结构稀疏性的建模方法,实现对深度网络模型参数的表征和裁剪。
此外,针对现有方法要预先训练一个未剪枝的大网络,然后再进行剪枝和微调的问题,提出从原始未训练的网络进行结构搜索,直接搜索得到一个剪枝后的轻量化网络,从而大幅减少网络训练和剪枝时间。
基于高斯尺度混合模型的深度网络剪枝方法
基于模型搜索的深度网络剪枝方法
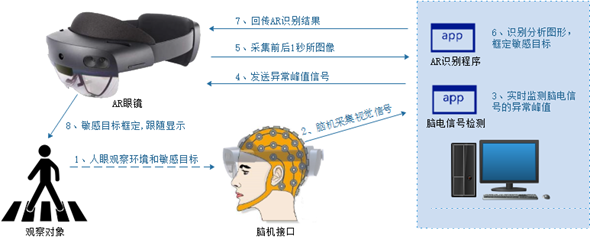
方向三:智能人机交互系统
针对现有智能人机交互系统离散的、精确的、单通道的以机器为中心的瓶颈性问题、研究连续的、语义的、多模态以人为中心的人机交互新方式。一方面,从人的角度,研究各类生理信号如脑电、肌电、眼动的高效采集与特征提取,实现人体意图解析、情绪调控以及脑纹识别;另一方面,从机的角度,构建基于语音、文字、计算机视觉的多类传感器态势感知系统,结合人工智能深度学习以及VR/AR显示技术的最新技术进展,将获取外界数据加以智能化分析综合,反馈给人,辅助人的判断,进而实现“人机知行合一”。
脑电信号分析 基于语音、文字、场景等识别的环境态势感知
方向四:并行计算研究
研究内容包括:基于硬件或微码状态机的并行处理结构、设计与实现;先进的微处理器体系架构及专用指令集处理器(ASIP)设计技术;并行处理系统体系结构及并行处理内核间数据交换网络结构与设计。
可编程大规模并行处理系统实物展示
方向五:神经网络处理器NNP研究
研究内容包括:典型深度学习网络算法工程化;通用CNN/SNN神经网络处理器系统编程和参数配置方法;网络处理器数据结构及高效数据交换方式;有限资源环境下神经网络处理器的设计与实现技术。
(研究内容之三 ━┅ 传输):
方向一:语义通信
基于人工智能技术研究智能语义通信。包括:语义的刻画与度量、语义符号的构建、语义编码和语义通信方案等。
(研究内容之四 ━┅ 评价):
方向一:图像语义评价
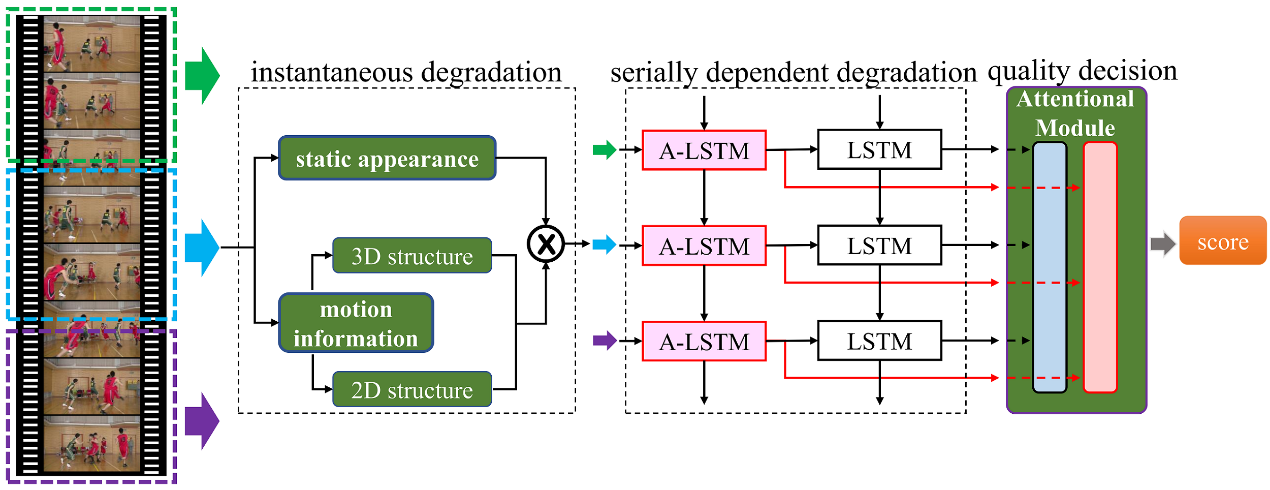
基于脑认知科学和人眼视觉感知理论,探索数字图像的视觉语义内容表征机理,构建基于大脑内在推导机制的图像语义感知模型和基于方位选择特性的视觉内容表征模型,研究基于结构集约化的视觉信息度量方法和脑启发式图像客观质量评价方法;探索用户的个性化语义属性挖掘和美学评价规则的表示机理,构建用户性格特质的预测模型和美学元知识的表示模型,研究性格特质指导的个性化图像美学评价方法和基于语义元学习的个性化图像美学语义评价方法。基于语义知识图谱理论,探索图像中的语义对象基元、语义背景基元之间的深层次作用机制,研究基于图卷积网络的图像情感语义评价方法。
基于长短时记忆关联的视频质量评价方法
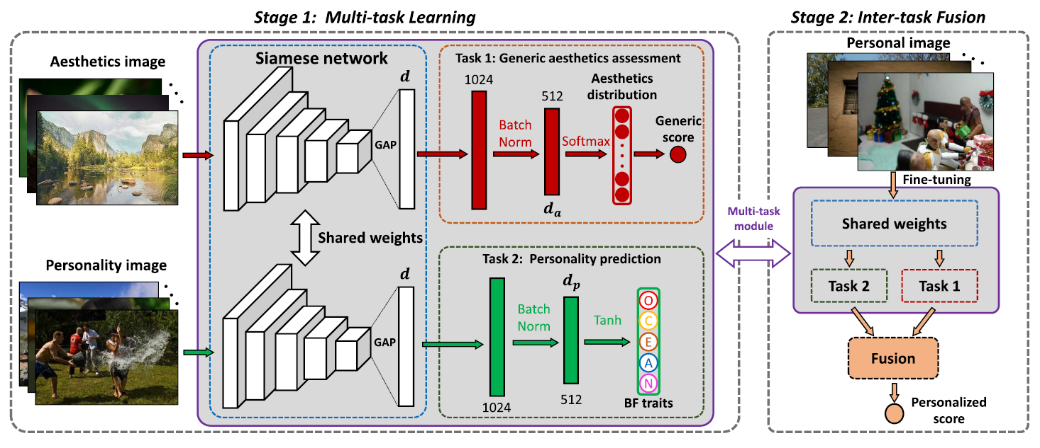
性格特质指导的个性化图像美学评价方法
(研究内容之五 ━┅ 认知):
方向一:类脑语义网络
针对目标检测、分类、识别等高级视觉任务,面向语义信息理解,利用深度学习技术及类脑语义网络,完成面向应用的“语义级”计算成像。
方向二:人体姿态估计
人体姿态估计旨在检测人体关节位置来描述人体姿态。可以通过人体关键点、图模型、基元的方式进行表示。基于人体关键点的高斯响应热图,设计多尺度特征融合模块,借鉴空间注意力机制,并通过多级网络结构细化和监督信息,隐式地学习捕获骨架点空间依赖关系,获取高效特征表示;基于图模型和人体几何先验,利用人体关键点连接构成的图结构约束,结合样本分布的空间先验知识,进行精细化建模;以人体关节点作为基元,将完整的人体表示为满足关节连接限制的语义层级模型,通过自底向上多级预测,自上而下知识引导有效推理,获得人体关键点精确表示。
方向三:行为识别算法研究
基于人体骨架数据,对人体行为实现判别性特征的提取。在涉及到人物交互的动作时,构建多模态网络模型,研究多模态数据下神经网络的决策机制,并对各模态之间的关系进行深层次挖掘和探究,利用各自特性设计模态融合模块,从不同角度综合描绘人体形态,对人体行为进行更全面客观的特征表示进而准确识别。
方向四:视觉人物交互识别
人物交互识别需在个体检测基础上,判别出人与物体的交互类别。基于深度卷积神经网络及循环神经网络等网络,结合跟踪检测及行为识别方法,对动态人与物体的交互行为进行判别。具体表现为利用交互关系的帧间信息,结合空间人物交互检测定位优势,使判别结果在时空维度上更加合理。视觉人物交互识别方法在监控下的特殊行为预警,商场购物需求分析,医院中病人监护等场合有广泛地应用。