祝贺!由西电人工智能学院石光明教授及其博士生焦阳撰写的学术论文在人工智能领域最具影响力的国际学术会议之一CVPR2021(IEEE Conf. on Computer Vision and Pattern Recognition)上发表!
日期:2020-01-15 00:02 点击量:
祝贺!由西电人工智能学院石光明教授及其博士生焦阳撰写的学术论文在人工智能领域最具影响力的国际学术会议之一CVPR2021(IEEE Conf. on Computer Vision and Pattern Recognition)上发表!CVPR也是计算机视觉和模式识别领域的三大顶级学术会议之一。
这是一篇有关无监督场景流(SceneFlow)联合估计的高质量论文!其原创思想由博士生焦阳提出,与石光明教授及约翰霍普金斯大学Trac D. Tran教授进行讨论后,联合指导完成。代码将在整理后开源。
 论文主题关键词:场景流估计(SceneFlow Estimation),光流,立体深度,相机姿态,场景刚性约束
论文主题关键词:场景流估计(SceneFlow Estimation),光流,立体深度,相机姿态,场景刚性约束
论文创新与贡献点:该论文摒弃现有方法中的实例分割网络,尝试从联合刚性像素推断的角度解决无监督场景流估计问题,通过设计新型场景流框架,联合光流-深度-相机姿态来学习不同子任务之间的内在几何关系,并基于此高效推断场景刚性像素区域,优化刚性约束,提升场景流估计的准确率与泛化性。
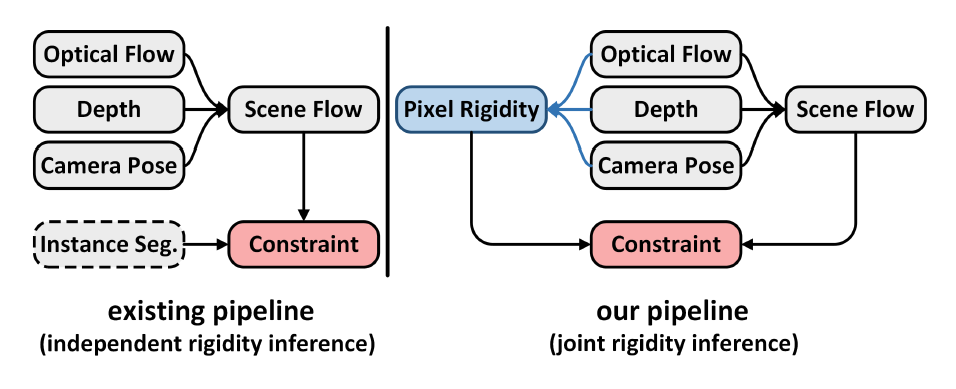 实验验证及结论:通过在国际通用真实驾驶场景KITTI数据库上的大量验证实验表明,本文提出的方法在泛化能力和评价准确性在场景流估计的四个子任务上(包括光流估计,深度估计,相机姿态估计与运动分割估计)均优于现有的无监督场景流估计技术。同时,高效的联合刚性推断无需额外的实例分割网络与训练,大幅减少了模型参数,提升了前向/反向传播速度。新方法是场景流任务中联合学习光流-深度-相机姿态进行刚性像素推断的首次尝试,将为视频场景理解、无监督场景流估计任务提供重要的借鉴意义和参考价值。
实验验证及结论:通过在国际通用真实驾驶场景KITTI数据库上的大量验证实验表明,本文提出的方法在泛化能力和评价准确性在场景流估计的四个子任务上(包括光流估计,深度估计,相机姿态估计与运动分割估计)均优于现有的无监督场景流估计技术。同时,高效的联合刚性推断无需额外的实例分割网络与训练,大幅减少了模型参数,提升了前向/反向传播速度。新方法是场景流任务中联合学习光流-深度-相机姿态进行刚性像素推断的首次尝试,将为视频场景理解、无监督场景流估计任务提供重要的借鉴意义和参考价值。
论文主要工作介绍如下:
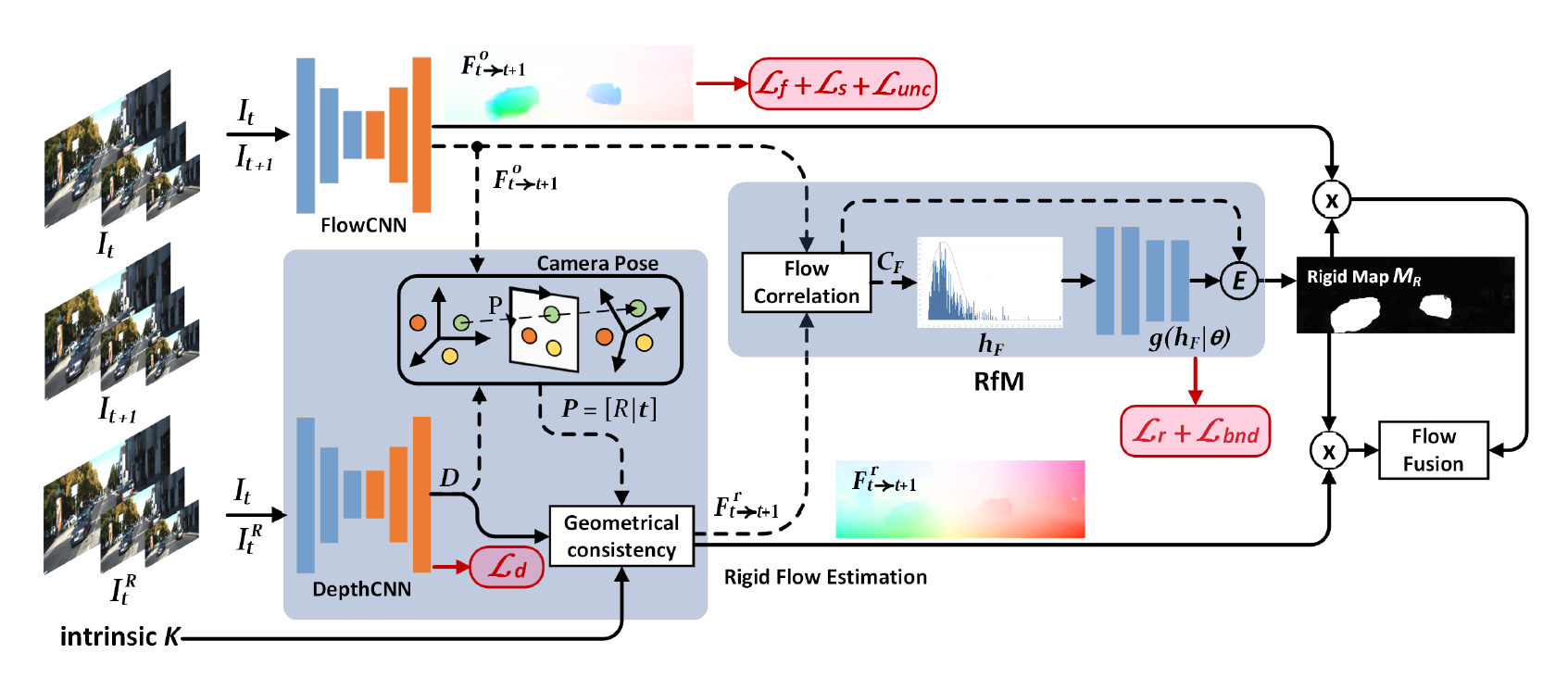
1. 利用基于梯度优化的深度学习框架设计光流卷积神经网络(FlowCNN)和立体深度估计网络(DepthCNN),并对其进行估计,得到光流场和深度场;
2. 利用Perspective-n-Point(PnP)方法优化连续两帧之间的三维空间像素投影,计算得到相机姿态矩阵P=[R|t],并联合场景深度计算全局运动。
3. 基于高斯混合模型(GMM)设计Rigid from Motion(RfM)模块,利用光流场、深度场以及姿态矩阵对刚性像素推断进行联合学习及推断,得到场景刚性分割掩码。
4. 基于刚性分割掩码对估计的运动进行刚性约束,并通过反向传播优化光度误差,训练得到高精度场景流估计模型EffiScene。

代码链接:整理后将开源
大会介绍:
CVPR(IEEE Conference on Computer Vision and Pattern Recognition)即IEEE国际计算机视觉与模式识别会议,是由IEEE举办的一年一度的计算机视觉和模式识别领域的顶级学术会议。该会议为人工智能领域最具影响力的国际学术会议之一,被中国计算机学会(CCF)认定为A类会议。
CVPR为世界顶级计算机视觉三大顶会之一,另外两个为ICCV和ECCV。
石光明教授团队介绍:
西电人工智能学院长江学者特聘教授石光明团队多年来面向国家重大战略需求和国际学术前沿,深耕人工智能理论及其相关工程应用领域,探索计算成像、类脑智能视觉感知、脑机混合增强智能、新一代深度学习理论与算法、图像视频建模与分析、无人驾驶等关键技术和学科前沿,开展了一系列具有开创性和前瞻性的研究工作,旨在推动脑机接口技术与人工智能的交叉研究。团队现有专职研究人员30人,包括教授9人、副教授8人,博师生导师10人,硕士生导师20余人,青年教师及博士后10余人,其中国家级人才、国家级青年人才、省部级人才、省部级青年人才等高层次人才20余人次。另有兼职人员两名:林维斯(新加坡南洋理工大学、华山学者讲座教授)、李小俚(北京师范大学)。
团队多年来在“千万级”基础加强项目、国家重点研发计划、国家自然科学基金重点项目、国家自然科学基金重大项目、国家自然科学基金仪器专项、优青基金、面上项目、高分重大专项等项目的支持下,聚焦类脑视觉感知、计算成像、脑机混合增强智能等关键技术研究,取得了一系列科研成果,发表了包括IEEE会刊(PAMI,IP,SP,MM)、IJCV、Brain Research、Neuroscience Letters、等国际权威期刊、本领域国际顶会CVPR、ICCV、ICML及其它国内外核心期刊/国际会议学术论文合计400余篇。至今,SCI他引约4000次,单篇最高480余次, Google Scholar引用超约8000次,授权发明专利100余项,其中美国授权专利一项。相关研究成果获国际会议最佳论文奖3项,荣获国家级自然科学二等奖1项、省部级科学技术一等奖1项、中国电子学会二等奖1项、国防科技进步奖三等奖1项。
第一作者焦阳个人简介:
 焦阳,博士研究生,西安电子科技大学人工智能学院。2015年获西安电子科技大学学士学位; 2015至2016年攻读西安电子科技大学硕士学位;2016年至今攻读西安电子科技大学博士学位,导师石光明教授;2019年至2021年,为美国约翰霍普金斯(the Johns Hopkins University)大学访问学者,国外导师Trac D. Tran教授。
焦阳,博士研究生,西安电子科技大学人工智能学院。2015年获西安电子科技大学学士学位; 2015至2016年攻读西安电子科技大学硕士学位;2016年至今攻读西安电子科技大学博士学位,导师石光明教授;2019年至2021年,为美国约翰霍普金斯(the Johns Hopkins University)大学访问学者,国外导师Trac D. Tran教授。
主要研究方向为光流与场景流估计,视频理解、人脸表情识别、细粒度图像识别、图像增强等,在IEEE TGRS、IEEE CVPR、IEEE VCIP、Elsevier PR等国内外期刊和会议上以第一作者发表论文4篇,申请专利4项,授权1项;重点参与国家自然科学基金项目2项。
这是一篇有关无监督场景流(SceneFlow)联合估计的高质量论文!其原创思想由博士生焦阳提出,与石光明教授及约翰霍普金斯大学Trac D. Tran教授进行讨论后,联合指导完成。代码将在整理后开源。
论文研究背景及创新点
场景流(SceneFlow)通过联合光流估计(x-y轴)和深度估计(z轴),描述了真实世界中像素级的三维运动过程,为众多实际应用,如自动驾驶等,提供了丰富的几何线索。目前,先进的场景流技术大都基于深度学习构建。为了避免训练过程中使用密集标签信号进行监督,基于光度误差(Photometric Loss)的无监督场景流估计成为了近年来的研究热点。然而,由于连续视频帧中的对应像素可能存在高混淆(high ambiguous)的投影关系,如少纹理、非结构区域,优化全局光度误差存在极大困难。因此,现有方法通过设计额外的实例分割网络(Instance Segmentation)来辅助估计刚性区域,并基于此进行刚性运动约束,减小光度误差。然而,这种架构将导致分割网络无法在无监督场景流任务上进行有效的训练,并且,独立于场景流任务的前向传播过程使得分割网络只能基于原始RGB像素进行推断,而无法从已估计的运动中获取信息。论文创新与贡献点:该论文摒弃现有方法中的实例分割网络,尝试从联合刚性像素推断的角度解决无监督场景流估计问题,通过设计新型场景流框架,联合光流-深度-相机姿态来学习不同子任务之间的内在几何关系,并基于此高效推断场景刚性像素区域,优化刚性约束,提升场景流估计的准确率与泛化性。
论文主要工作介绍如下:
研究方法
本研究基于场景刚性先验,利用基于梯度优化的深度学习方法及设计刚性联合推理模块,获取具有高效的场景刚性分割结果及场景流估计模型EffiScene。
图1 EffiScene研究方法框架
1. 利用基于梯度优化的深度学习框架设计光流卷积神经网络(FlowCNN)和立体深度估计网络(DepthCNN),并对其进行估计,得到光流场和深度场;
2. 利用Perspective-n-Point(PnP)方法优化连续两帧之间的三维空间像素投影,计算得到相机姿态矩阵P=[R|t],并联合场景深度计算全局运动。
3. 基于高斯混合模型(GMM)设计Rigid from Motion(RfM)模块,利用光流场、深度场以及姿态矩阵对刚性像素推断进行联合学习及推断,得到场景刚性分割掩码。
4. 基于刚性分割掩码对估计的运动进行刚性约束,并通过反向传播优化光度误差,训练得到高精度场景流估计模型EffiScene。
实验结果展示
本研究在国际通用真实车辆驾驶数据集KITTI Raw上进行无监督训练,并在KITTI 2012/2015/Odometry上进行大量测试及蒸馏实验。结果表明,相对于目前SOTA方法,所提技术在场景流四个不同子任务上均有明显提升。实验结果见表1至表4。
表1 KITTI 2012 & 2015数据集上光流估计性能
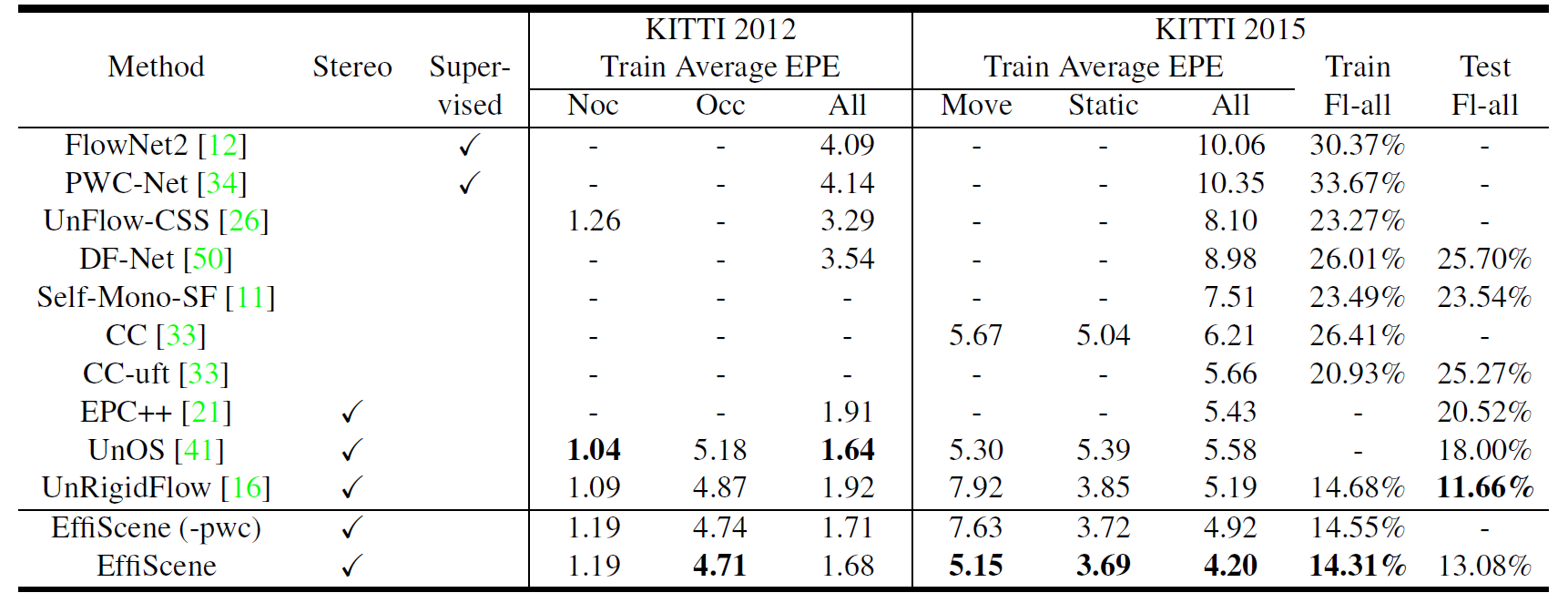
表2 KITTI 2015数据集立体视觉深度估计性能
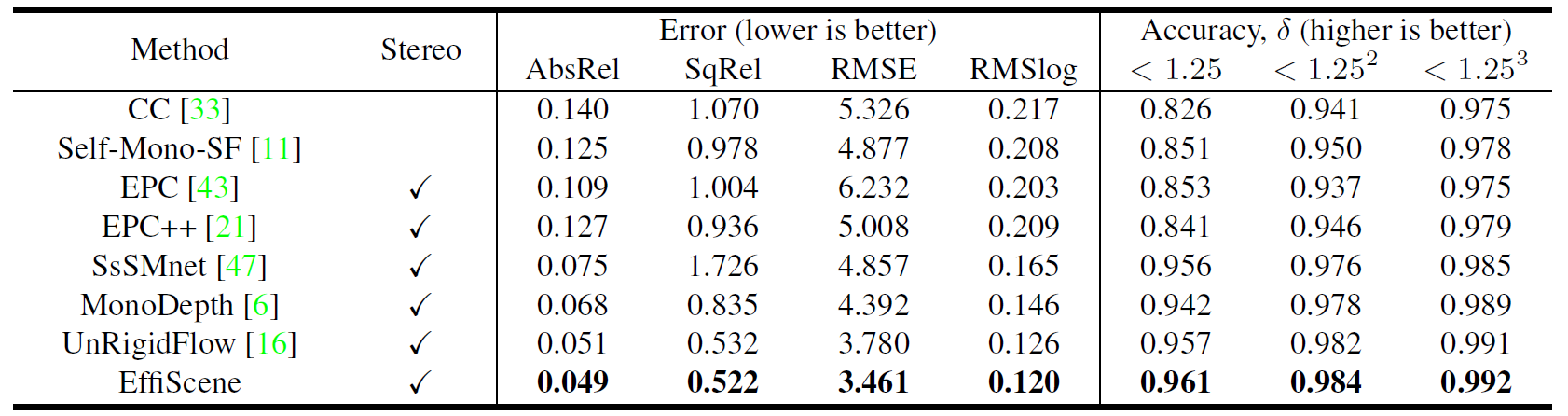
表3 KITTI Odometry数据集相机姿态估计性能
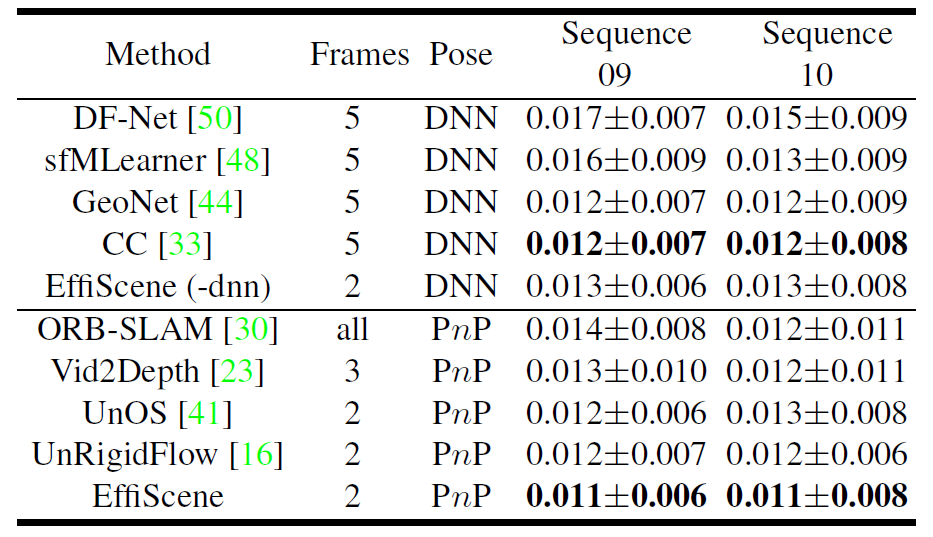
表4 KITTI 2015数据集运动分割(刚性分割)性能

图2展示了所提出的EffiScene方法估计的场景流可视化图,包括光流(est. optical flow)、刚性流(est. global motion)、深度(est. depth)、运动分割(est. segmentation)等。可以看到运动物体可以较好的与场景刚性区域分开,得到较为锐利的分割边缘,进一步证明了本研究方法通过联合学习光流-深度-相机姿态进行刚性推断的可行性与高效性。
表2 KITTI 2015数据集立体视觉深度估计性能
表3 KITTI Odometry数据集相机姿态估计性能
表4 KITTI 2015数据集运动分割(刚性分割)性能
图2 EffiScene场景流估计可视化结果图
论文链接:https://arxiv.org/abs/2011.08332代码链接:整理后将开源
大会介绍:
CVPR(IEEE Conference on Computer Vision and Pattern Recognition)即IEEE国际计算机视觉与模式识别会议,是由IEEE举办的一年一度的计算机视觉和模式识别领域的顶级学术会议。该会议为人工智能领域最具影响力的国际学术会议之一,被中国计算机学会(CCF)认定为A类会议。
CVPR为世界顶级计算机视觉三大顶会之一,另外两个为ICCV和ECCV。
石光明教授团队介绍:
西电人工智能学院长江学者特聘教授石光明团队多年来面向国家重大战略需求和国际学术前沿,深耕人工智能理论及其相关工程应用领域,探索计算成像、类脑智能视觉感知、脑机混合增强智能、新一代深度学习理论与算法、图像视频建模与分析、无人驾驶等关键技术和学科前沿,开展了一系列具有开创性和前瞻性的研究工作,旨在推动脑机接口技术与人工智能的交叉研究。团队现有专职研究人员30人,包括教授9人、副教授8人,博师生导师10人,硕士生导师20余人,青年教师及博士后10余人,其中国家级人才、国家级青年人才、省部级人才、省部级青年人才等高层次人才20余人次。另有兼职人员两名:林维斯(新加坡南洋理工大学、华山学者讲座教授)、李小俚(北京师范大学)。
团队多年来在“千万级”基础加强项目、国家重点研发计划、国家自然科学基金重点项目、国家自然科学基金重大项目、国家自然科学基金仪器专项、优青基金、面上项目、高分重大专项等项目的支持下,聚焦类脑视觉感知、计算成像、脑机混合增强智能等关键技术研究,取得了一系列科研成果,发表了包括IEEE会刊(PAMI,IP,SP,MM)、IJCV、Brain Research、Neuroscience Letters、等国际权威期刊、本领域国际顶会CVPR、ICCV、ICML及其它国内外核心期刊/国际会议学术论文合计400余篇。至今,SCI他引约4000次,单篇最高480余次, Google Scholar引用超约8000次,授权发明专利100余项,其中美国授权专利一项。相关研究成果获国际会议最佳论文奖3项,荣获国家级自然科学二等奖1项、省部级科学技术一等奖1项、中国电子学会二等奖1项、国防科技进步奖三等奖1项。
第一作者焦阳个人简介:
焦阳,博士研究生,西安电子科技大学人工智能学院。2015年获西安电子科技大学学士学位; 2015至2016年攻读西安电子科技大学硕士学位;2016年至今攻读西安电子科技大学博士学位,导师石光明教授;2019年至2021年,为美国约翰霍普金斯(the Johns Hopkins University)大学访问学者,国外导师Trac D. Tran教授。主要研究方向为光流与场景流估计,视频理解、人脸表情识别、细粒度图像识别、图像增强等,在IEEE TGRS、IEEE CVPR、IEEE VCIP、Elsevier PR等国内外期刊和会议上以第一作者发表论文4篇,申请专利4项,授权1项;重点参与国家自然科学基金项目2项。
